HanLP/tok_restful.ipynb at doc-zh · hankcs/HanLP (github.com)
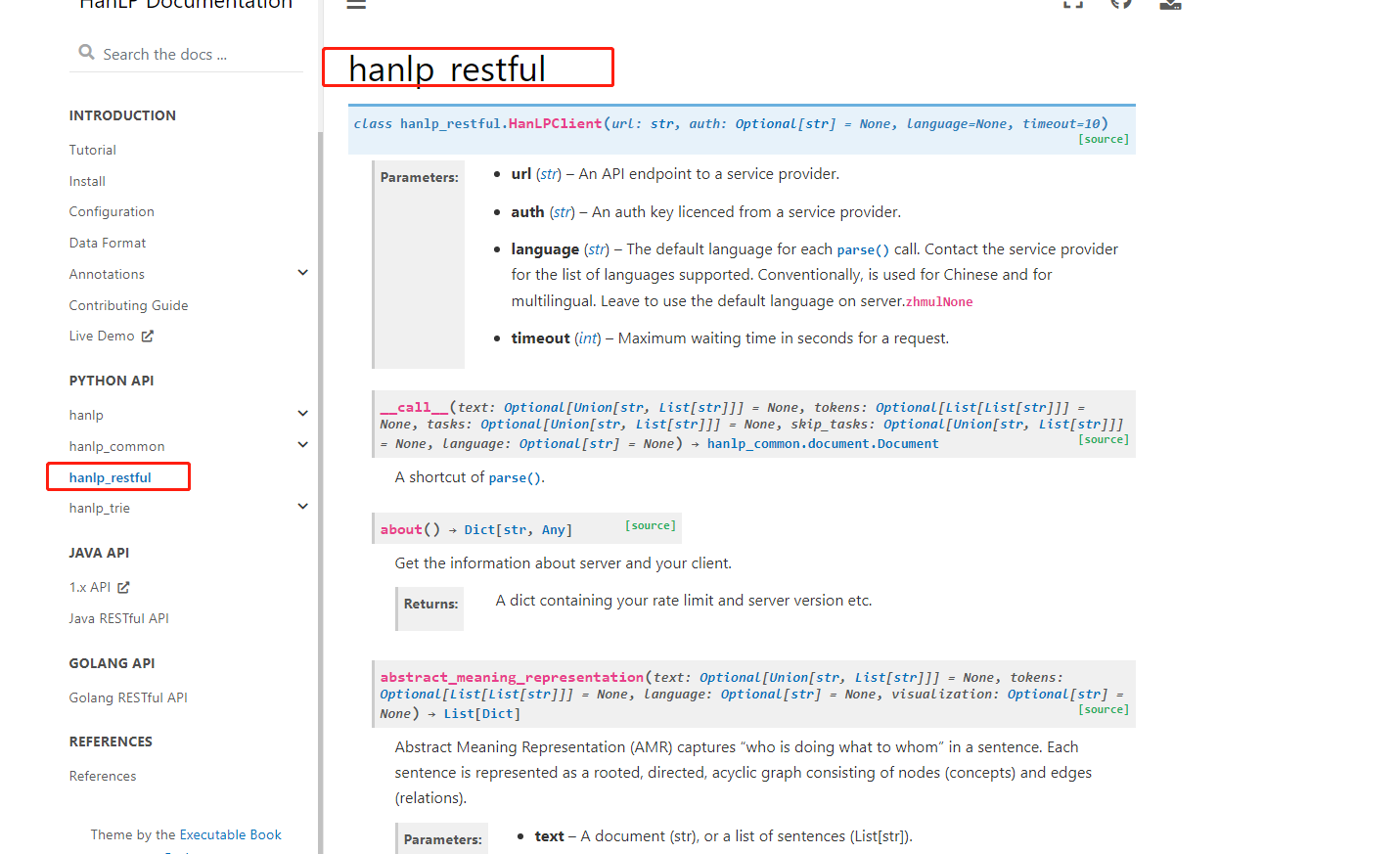
" HanLP.tokenize(‘商品和服务。阿婆主来到北京立方庭参观自然语义科技公司’, coarse=True) "
按照上面的教程测试粗粒度分词功能,但是我用了代码之后却是报错的状态,请问我该如何修改?下面的是我的代码和报错
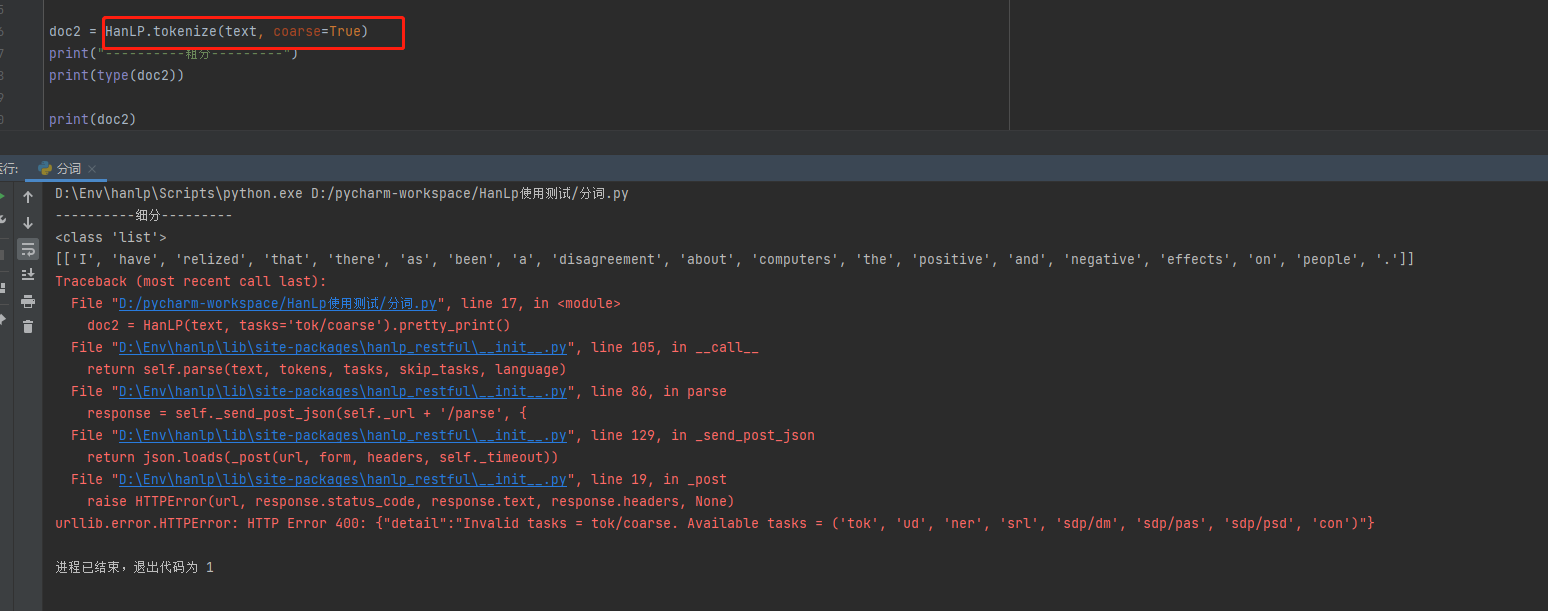
英文不支持粗分。
请问在hanlp_restful诸多接口中,哪些是支持英文( 设置language=‘mul’)的,因为我在用词性标注的时候也发现设置成mul是不可以的,虽然设置成zh,然后文本用英文也能给我结果,但是对结果还是抱有怀疑态度的,所以希望告知哪些可以用英文,哪些不可以,谢谢!
线上服务没有?那么我是否可以理解为本地库hanlp接口是否有其他支持英文的,还是说基本都是这几个支持英文,如果有本地接口有其他接口支持英文,那么是哪几个?谢谢!
另外希望能够优化相对应的文档说明,我感觉不不管是在上方的英文文档,还是在GitHub上的中文功能教程,都没有一个比较全面的对功能介绍说明,实在是对新手不是很友好,需要投入大量时间,期待后续能够看到更加容易理解的文档。
建议看文档以_EN结尾的模型有几个。设计上任何语言都支持,实际上受限于版权不是每个语种x每个模型都会发布。
的确,现在的文档无法带着新手入门,要带新手入门也不是一个文档就足够的。一百多种语言乘以十几个任务,每个任务两三种模型,绝对不在新手能理解的范围。对于新手,建议的策略是仔细阅读文档,文档里有的功能,能理解多少就是多少。目前的中文demo,已经耗费了我们大量的精力去编写,目前的标注集说明,HanLP可能是世界上最全面的。新手阅读文档投入的时间,相较于我们维护文档、维护开源项目的时间,其实不值一提。我们要把文档写到新手能理解的话,所投入的时间太多,挤占了我们研发新技术的周期,可能无法承受。
2赞
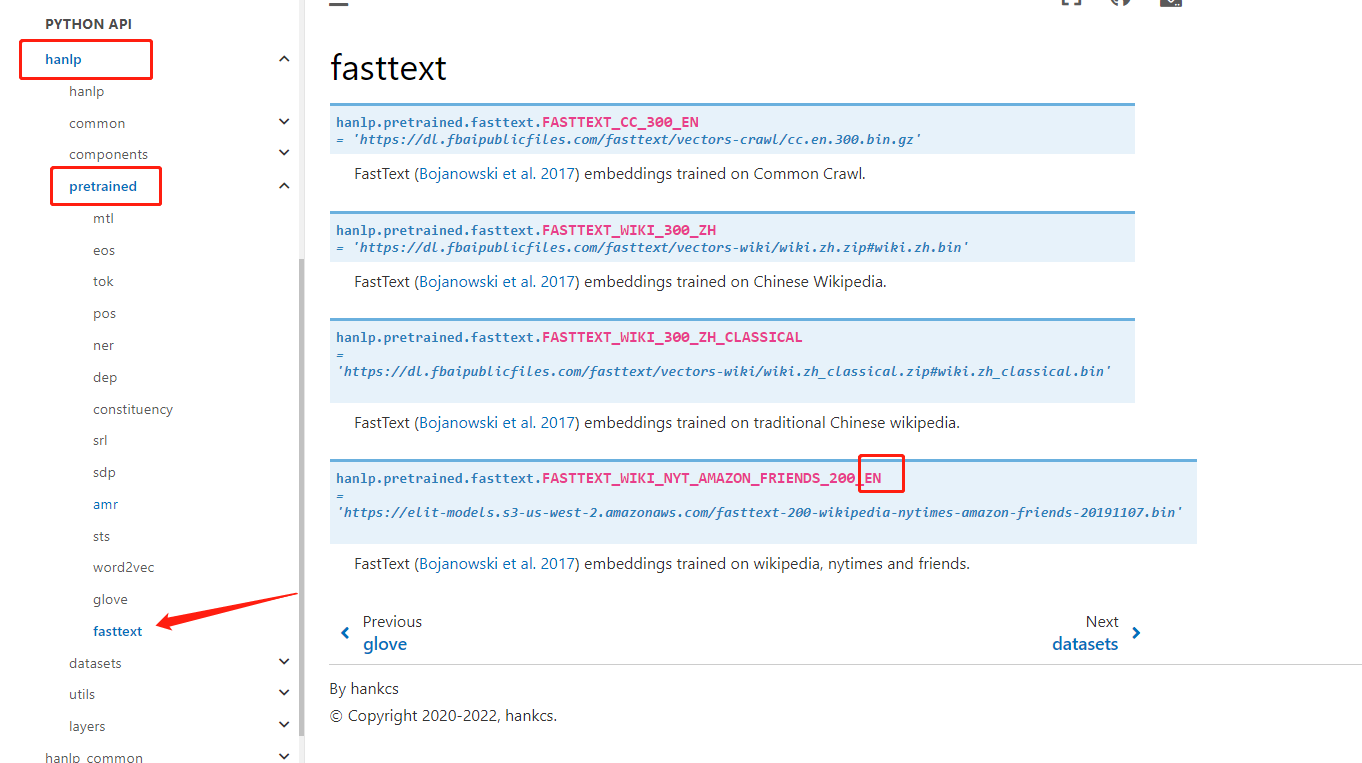
请问我这英文模型找的对不对?如果对的话请问这个最后的fasttest对应的是哪个功能呢,我在GitHub上目前还没有找到对应的解释,自己翻译称快速文本也感觉不太对,也不清楚具体是做什么的。希望告知具体的中文含义以及对应的功能作用。再次感谢!