问题描述
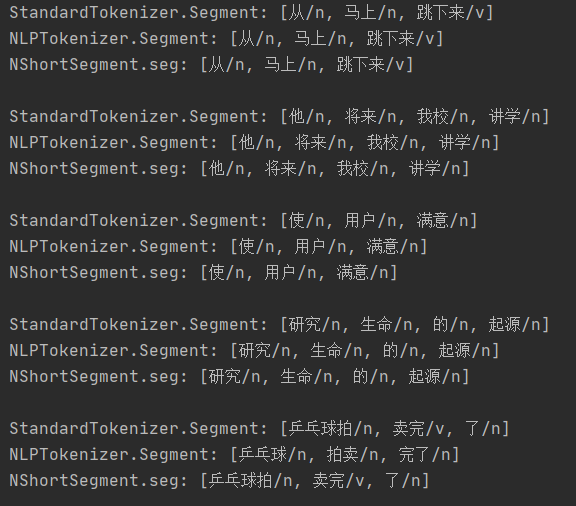
hanlp分词器把所有词词性分为名词,如图。为什么会出现这种现象?
问题还原
我曾经用PKU2005的语料库训练感知机和CRF分词器,但因为PKU2005语料库只有分词没有词性,于是我就给全部分词加了 \n 的名词词性来训练。如:
# 训练样本示例
迈向/n 充满/n 希望/n 的/n 新/n 世纪/n ——/n 一九九八年/n 新年/n 讲话/n (/n 附/n 图片/n 1/n 张/n )/n
我怀疑是不是这个原因导致,我现在用基于词典或基于模型的分词器分词结果都是名词词性。
所以这是hanlp中的什么机制导致的呢?模型训练的语料库影响全局的词性统计?怎么修正这种现象呢?
问题解决
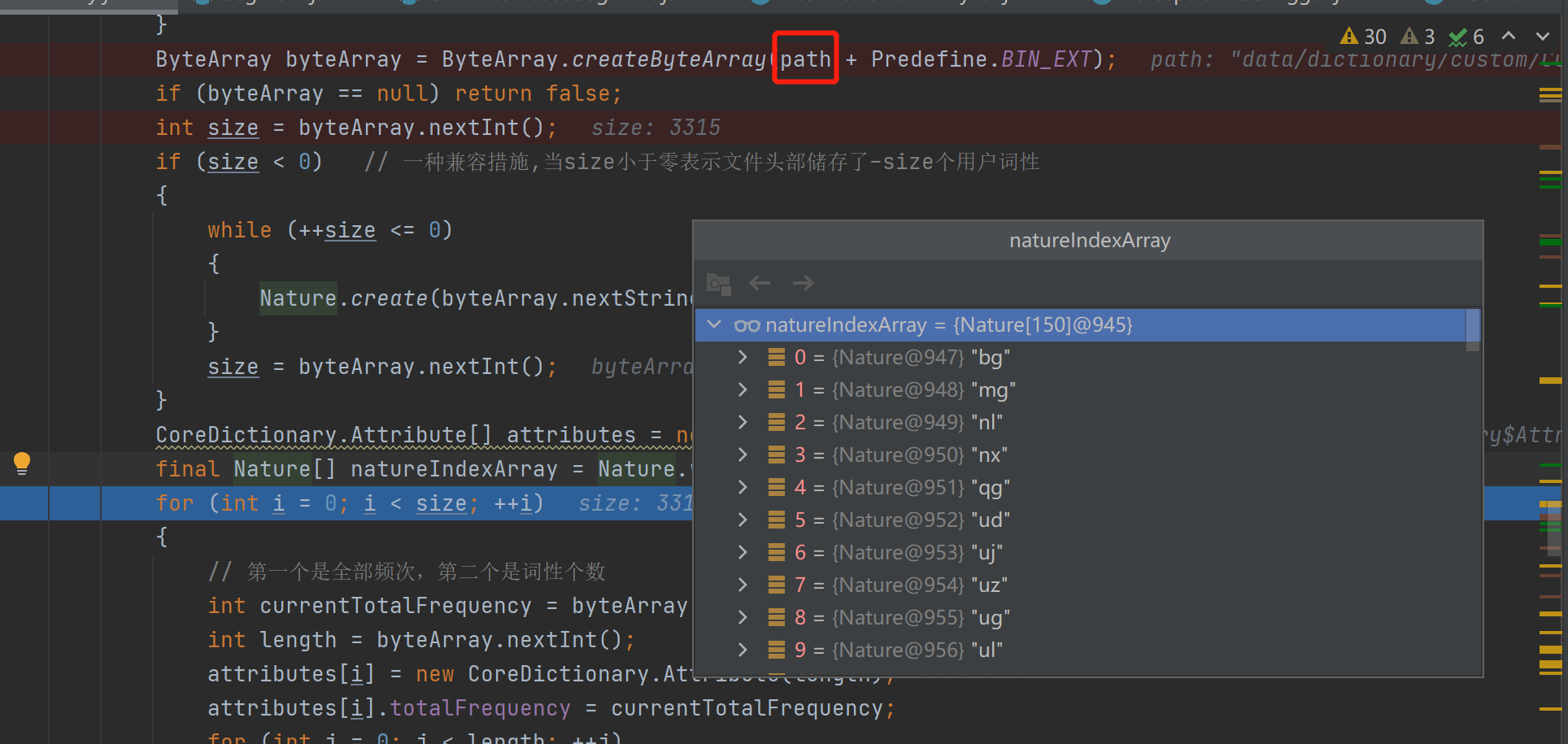
- 把Java工程中词典缓存的
.bin文件删除,修复Java项目的词性标注结果 - 把python site-package中词典缓存的
.bin文件删除,修复命令行的词性标注结果
但还是想知道原理,望解答。