
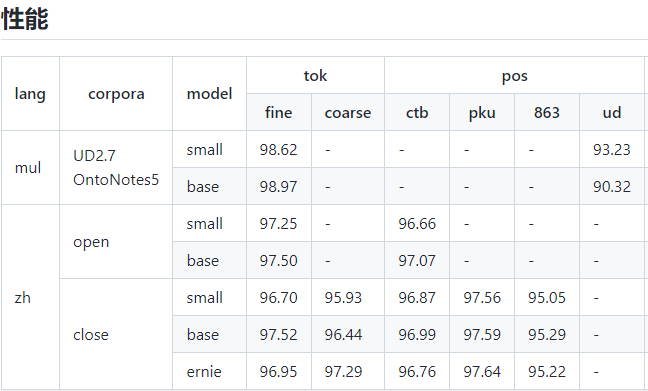
经过一年的打磨,HanLP2.1已经于元旦为大家贺岁。这次2.1为全新设计,带来了许多新功能与准确率提升。HanLP2.1支持中英日法等在内的104种语言的十多种任务:
| 功能 | RESTful | 多任务 | 单任务 | 模型 | 标注标准 |
|---|---|---|---|---|---|
| 分词 | 教程 | 教程 | 教程 | tok | 粗分、细分 |
| 词性标注 | 教程 | 教程 | 教程 | pos | CTB、PKU、863 |
| 命名实体识别 | 教程 | 教程 | 教程 | ner | PKU、MSRA、OntoNotes |
| 依存句法分析 | 教程 | 教程 | 教程 | dep | SD、UD、PMT |
| 成分句法分析 | 教程 | 教程 | 教程 | con | Chinese Tree Bank |
| 语义依存分析 | 教程 | 教程 | 教程 | sdp | CSDP |
| 语义角色标注 | 教程 | 教程 | 教程 | srl | Chinese Proposition Bank |
| 抽象意义表示 | 教程 | 暂无 | 教程 | amr | CAMR |
| 指代消解 | 教程 | 暂无 | 暂无 | 暂无 | OntoNotes |
| 语义文本相似度 | 教程 | 暂无 | 教程 | sts | 暂无 |
| 文本风格转换 | 教程 | 暂无 | 暂无 | 暂无 | 暂无 |
| 关键词短语提取 | 教程 | 暂无 | 暂无 | 暂无 | 暂无 |
| 抽取式自动摘要 | 教程 | 暂无 | 暂无 | 暂无 | 暂无 |
| 生成式自动摘要 | 教程 | 暂无 | 暂无 | 暂无 | 暂无 |
| 文本语法纠错 | 教程 | 暂无 | 暂无 | 暂无 | 暂无 |
| 文本分类 | 教程 | 暂无 | 暂无 | 暂无 | 暂无 |
| 情感分析 | 教程 | 暂无 | 暂无 | 暂无 | [-1,+1] |
| 语种检测 | 教程 | 暂无 | 教程 | 暂无 | ISO 639-1编码 |
其中,RESTful API可能最受大家期待。我们决定上线社区API方便大家快速体验HanLP2.1,RESTful API的调用演示如下:
Python
安装客户端:
pip install hanlp_restful
调用:
from hanlp_restful import HanLPClient
HanLP = HanLPClient('https://www.hanlp.com/api', auth='你申请到的auth') # auth需要申请
doc = HanLP.parse('2021年HanLPv2.1为生产环境带来次世代最先进的多语种NLP技术。阿婆主来到北京立方庭参观自然语义科技公司。')
Java
添加下列依赖到pom.xml中:
<dependency>
<groupId>com.hankcs.hanlp.restful</groupId>
<artifactId>hanlp-restful</artifactId>
<version>0.0.14</version>
</dependency>
请将上面的版本号修改为文档中的最新版:Java RESTful API — HanLP Documentation
调用:
HanLPClient client = new HanLPClient("https://www.hanlp.com/api", '你申请到的auth'); //第二个参数秘钥,需要申请
System.out.println(client.parse("2021年HanLPv2.1为生产环境带来次世代最先进的多语种NLP技术。阿婆主来到北京立方庭参观自然语义科技公司。"));
输出:
{
"tok/fine": [
["2021年", "HanLPv2.1", "为", "生产", "环境", "带来", "次", "世代", "最", "先进", "的", "多", "语种", "NLP", "技术", "。"],
["阿婆主", "来到", "北京", "立方庭", "参观", "自然", "语义", "科技", "公司", "。"]
],
"tok/coarse": [
["2021年", "HanLPv2.1", "为", "生产", "环境", "带来", "次世代", "最", "先进", "的", "多语种", "NLP", "技术", "。"],
["阿婆主", "来到", "北京立方庭", "参观", "自然语义科技公司", "。"]
],
"pos/ctb": [
["NT", "NR", "P", "NN", "NN", "VV", "JJ", "NN", "AD", "JJ", "DEG", "CD", "NN", "NR", "NN", "PU"],
["NN", "VV", "NR", "NR", "VV", "NN", "NN", "NN", "NN", "PU"]
],
"pos/pku": [
["t", "nx", "p", "vn", "n", "v", "b", "n", "d", "a", "u", "a", "n", "nx", "n", "w"],
["n", "v", "ns", "ns", "v", "n", "n", "n", "n", "w"]
],
"pos/863": [
["nt", "w", "p", "v", "n", "v", "a", "nt", "d", "a", "u", "a", "n", "ws", "n", "w"],
["n", "v", "ns", "n", "v", "n", "n", "n", "n", "w"]
],
"ner/pku": [
[],
[["北京立方庭", "ns", 2, 4], ["自然语义科技公司", "nt", 5, 9]]
],
"ner/msra": [
[["2021年", "DATE", 0, 1], ["HanLPv2.1", "WWW", 1, 2]],
[["北京", "LOCATION", 2, 3], ["立方庭", "LOCATION", 3, 4], ["自然语义科技公司", "ORGANIZATION", 5, 9]]
],
"ner/ontonotes": [
[["2021年", "DATE", 0, 1], ["HanLPv2.1", "ORG", 1, 2]],
[["北京立方庭", "FAC", 2, 4], ["自然语义科技公司", "ORG", 5, 9]]
],
"srl": [
[[["2021年", "ARGM-TMP", 0, 1], ["HanLPv2.1", "ARG0", 1, 2], ["为生产环境", "ARG2", 2, 5], ["带来", "PRED", 5, 6], ["次世代最先进的多语种NLP技术", "ARG1", 6, 15]], [["最", "ARGM-ADV", 8, 9], ["先进", "PRED", 9, 10], ["技术", "ARG0", 14, 15]]],
[[["阿婆主", "ARG0", 0, 1], ["来到", "PRED", 1, 2], ["北京立方庭", "ARG1", 2, 4]], [["阿婆主", "ARG0", 0, 1], ["参观", "PRED", 4, 5], ["自然语义科技公司", "ARG1", 5, 9]]]
],
"dep": [
[[6, "tmod"], [6, "nsubj"], [6, "prep"], [5, "nn"], [3, "pobj"], [0, "root"], [8, "amod"], [15, "nn"], [10, "advmod"], [15, "rcmod"], [10, "assm"], [13, "nummod"], [15, "nn"], [15, "nn"], [6, "dobj"], [6, "punct"]],
[[2, "nsubj"], [0, "root"], [4, "nn"], [2, "dobj"], [2, "conj"], [9, "nn"], [9, "nn"], [9, "nn"], [5, "dobj"], [2, "punct"]]
],
"sdp": [
[[[6, "Time"]], [[6, "Exp"]], [[5, "mPrep"]], [[5, "Desc"]], [[6, "Datv"]], [[13, "dDesc"]], [[0, "Root"], [8, "Desc"], [13, "Desc"]], [[15, "Time"]], [[10, "mDegr"]], [[15, "Desc"]], [[10, "mAux"]], [[8, "Quan"], [13, "Quan"]], [[15, "Desc"]], [[15, "Nmod"]], [[6, "Pat"]], [[6, "mPunc"]]],
[[[2, "Agt"], [5, "Agt"]], [[0, "Root"]], [[4, "Loc"]], [[2, "Lfin"]], [[2, "ePurp"]], [[8, "Nmod"]], [[9, "Nmod"]], [[9, "Nmod"]], [[5, "Datv"]], [[5, "mPunc"]]]
],
"con": [
["TOP", [["IP", [["NP", [["NT", ["2021年"]]]], ["NP", [["NR", ["HanLPv2.1"]]]], ["VP", [["PP", [["P", ["为"]], ["NP", [["NN", ["生产"]], ["NN", ["环境"]]]]]], ["VP", [["VV", ["带来"]], ["NP", [["ADJP", [["NP", [["ADJP", [["JJ", ["次"]]]], ["NP", [["NN", ["世代"]]]]]], ["ADVP", [["AD", ["最"]]]], ["VP", [["JJ", ["先进"]]]]]], ["DEG", ["的"]], ["NP", [["QP", [["CD", ["多"]]]], ["NP", [["NN", ["语种"]]]]]], ["NP", [["NR", ["NLP"]], ["NN", ["技术"]]]]]]]]]], ["PU", ["。"]]]]]],
["TOP", [["IP", [["NP", [["NN", ["阿婆主"]]]], ["VP", [["VP", [["VV", ["来到"]], ["NP", [["NR", ["北京"]], ["NR", ["立方庭"]]]]]], ["VP", [["VV", ["参观"]], ["NP", [["NN", ["自然"]], ["NN", ["语义"]], ["NN", ["科技"]], ["NN", ["公司"]]]]]]]], ["PU", ["。"]]]]]]
]
}
同时,Python HanLP提供基于等宽字体的可视化:
doc.pretty_print()
能够直接将语言学结构在你的控制台内可视化出来:
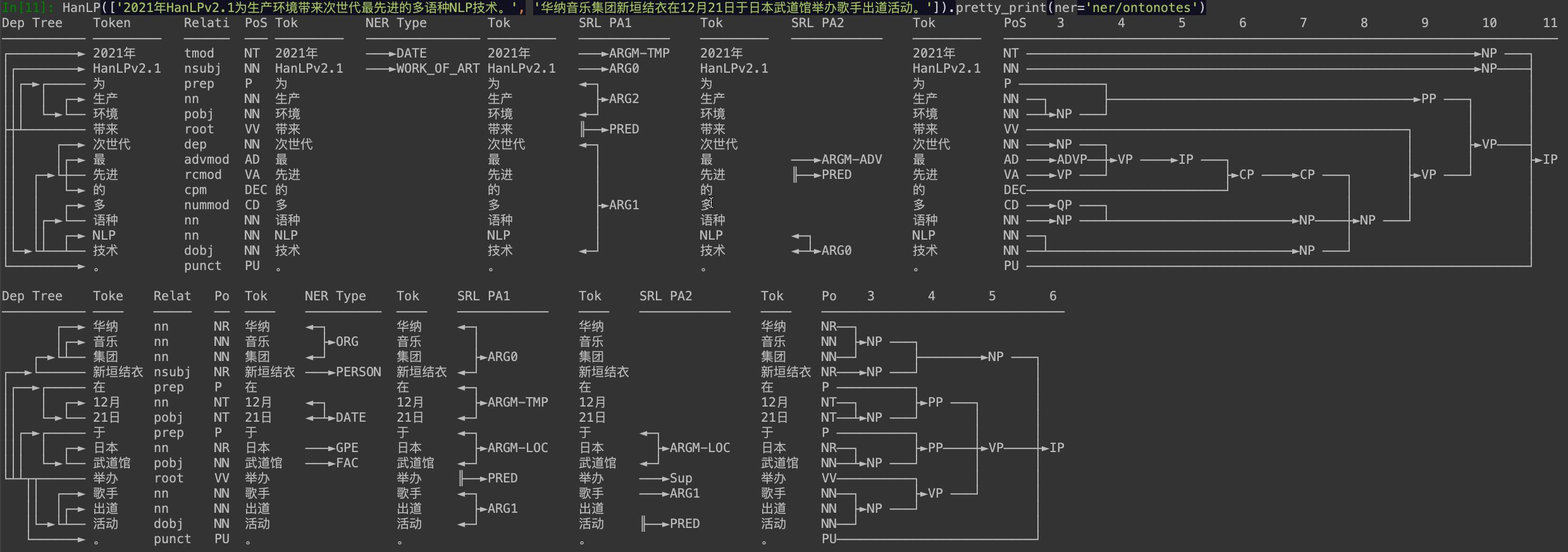
为了降低安装和部署的成本,也为了回馈开源社区,我们专门拿出服务器运行社区版API做公益。
社区版API面向学术界NLP研究者和公司技术选型人员免费提供,不收取任何费用亦不提供任何担保。社区版API通过本社区进行身份认证,并根据用户对开源社区的贡献分配调用额度。调用额度以每分钟的请求数度量,针对parse接口,每个请求最大可分析256个句子,约为1.5万字。
| 开源贡献 | 调用额度 |
|---|---|
| 论坛信用评级Lv1 | 4 |
| 论坛信用评级Lv2 | 20 |
| 论坛信用评级Lv3 | 30 |
| 论坛每获得10个赞 | +10 |
| 论坛绑定edu邮箱 | +10 |
| GitHub上为HanLP加星 | +40 |
| GitHub上fork HanLP | +6 |
| GitHub上每找出HanLP的一个bug | +20 |
| GitHub上每为HanLP提交一次代码 | +20 |
例如,你在论坛上信用评级为Lv1,同时在GitHub上为HanLP加了星并fork的话,你的调用额度总计为每分钟4+40+6=50个请求,等于12800个句子或75万个字符。虽然请求数看上去不高,但由于一个请求可以分析多个句子,最终吞吐量还是比较可观。由于庞大的用户数和有限且昂贵的GPU资源,我们暂时约定这个额度,但未来极有可能等比扩大调用频率。
我们也将根据你的开源贡献,定期更新你的调用额度。请在论坛上绑定GitHub账户,以便我们统计你的开源贡献。
申请方法
- 访问https://github.com/,登录自己的账号,没有GitHub账号的,需要注册一个后再登录
- 访问https://github.com/hankcs/HanLP
- 依次点击右上角
Star和Fork两个按钮,如下图

-
Fork需要几秒钟才能完毕,如下图所示,打码处是你的GitHub账号名

- 确保
Star和Fork已经完成,再访问https://bbs.hanlp.com,点击右上角“登录”,并选择用GitHub登录。登录时请不要修改用户名,保持与GitHub一致(重要!):

-
登录成功后,访问https://bbs.hanlp.com/u/hanlpbot,点击右上角
私信
-
私信标题:
申请API -
私信正文:复制下面全部文字,认真填写好后发送即可。我们将在一个工作日内完成审核并且将API秘钥以私信/短信的方式回复给你。

## 姓名
## 单位
## 联系电话
<!-- 请填写手机号以便接收秘钥auth -->
## 专业/行业
## 申请下列API
<!-- 括号内输入x勾选,可多选 -->
- [] 分词
- [] 词性标注
- [] 命名实体识别
- [] 依存句法分析
- [] 短语结构分析
- [] 语义角色标注
- [] 语义依存分析
- [] 语义文本相似度
- [] 文本风格转换
- [] 指代消解
- [] 抽象意义表示
- [] 关键词提取
- [] 抽取式自动摘要
- [] 生成式自动摘要
- [] 文本分类
- [] 情感分析
- [] 语种检测
## 免责声明
我已同意:HanLP中文社区提供的社区版API仅供技术选型和学术研究使用,不得用于其他目的。该API不提供任何担保,包括但不限于准确率、稳定性和响应速度。该API的调用额度的解释权归API运营方所有,且运营方有权随时进行调整而不另行通知。使用API时必须遵守当地法律法规,API运营方有权将使用记录提供给司法机构。
#### 申请人签名:

申请表为markdown格式,请留意格式问题,以免影响审核。感谢 @jinlina 编写的申请流程,对小白用户特别有帮助。
文档
HanLP的在线文档地址为:HanLP: Han Language Processing — HanLP Documentation
标注集的说明文档位于:Annotations — HanLP Documentation
 过两天试一试
过两天试一试