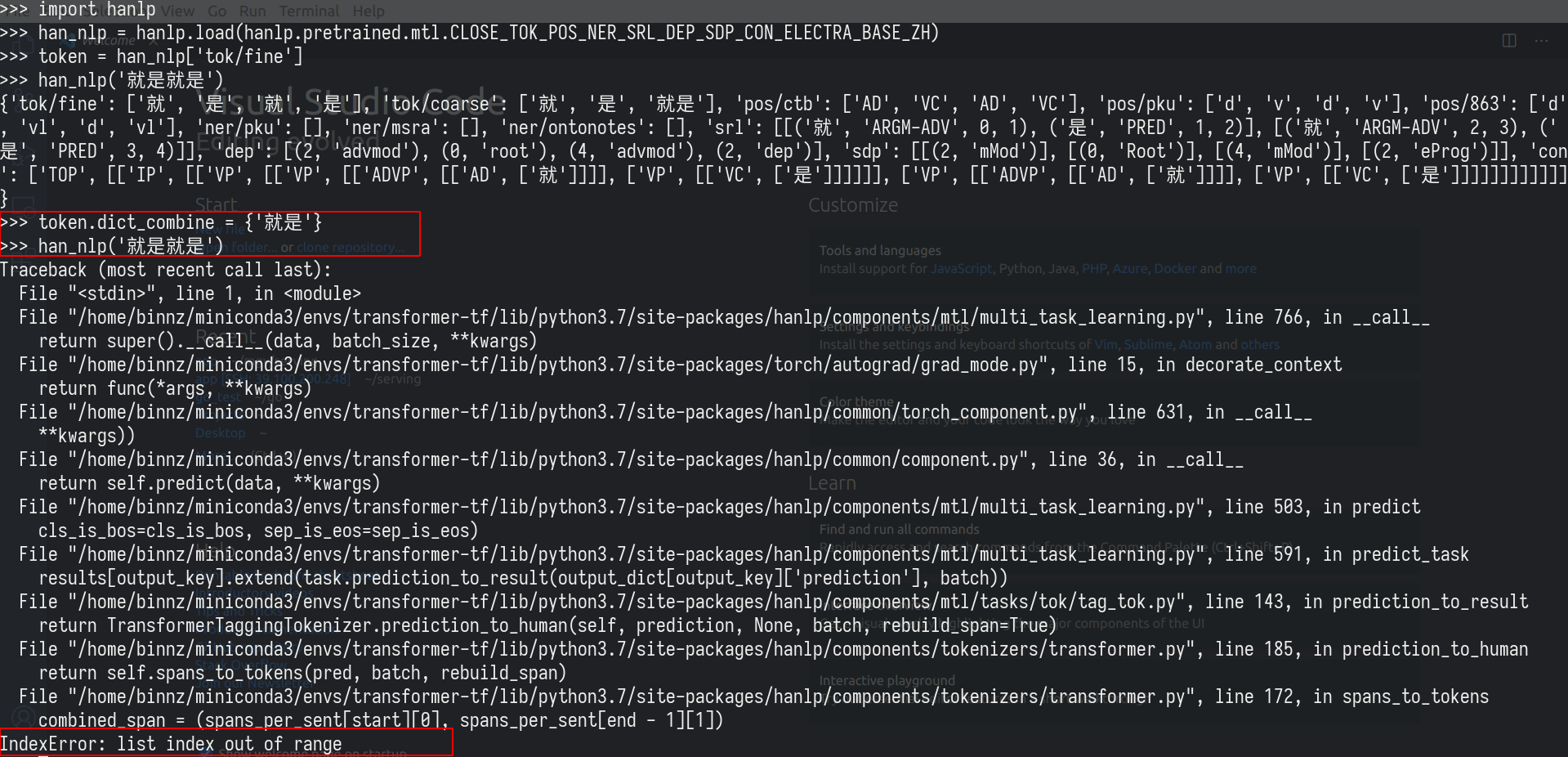
加入token_combine = {‘你好’}
han_nlp(‘你好你好’)也是报错
就是这样的pattern报错

# -*- coding:utf-8 -*-
# Author: hankcs
# Date: 2020-12-15 22:26
import hanlp
from hanlp.components.mtl.multi_task_learning import MultiTaskLearning
from hanlp.components.mtl.tasks.tok.tag_tok import TaggingTokenization
from tests import cdroot
cdroot()
HanLP: MultiTaskLearning = hanlp.load(hanlp.pretrained.mtl.CLOSE_TOK_POS_NER_SRL_DEP_SDP_CON_ELECTRA_S MALL_ZH)
tok: TaggingTokenization = HanLP['tok/fine']
# tok.dict_force = tok.dict_combine = None
# print(f'不挂词典:\n{HanLP("商品和服务行业")["tok/fine"]}')
#
# tok.dict_force = {'和服', '服务行业'}
# print(f'强制模式:\n{HanLP("商品和服务行业")["tok/fine"]}') # 慎用,详见《自然语言处理入 门》第二章
#
# tok.dict_force = {'和服务': ['和', '服务']}
# print(f'强制校正:\n{HanLP("正向匹配商品和服务、任何和服务必按上述切分")["tok/fine"]}')
tok.dict_force = None
tok.dict_combine = {'和服', '服务行业'}
print(f'合并模式:\n{HanLP("商品和服务行业")["tok/fine"]}')
# 需要算法基础才能理解,初学者可参考 http://nlp.hankcs.com/book.php
# See also https://hanlp.hankcs.com/docs/api/hanlp/components/tokenizers/transformer.html
https://github.com/hankcs/HanLP/blob/master/plugins/hanlp_demo/hanlp_demo/zh/demo_custom_dict.py