
一般转换的文本都是繁简夹杂的,想在转换的过程中识别出需要转换的汉字位置,这样可以让使用者再原文标注。
繁2简时,如果有地方获取一个检索到繁体字以及在什么位置的关系表,如[{ 繁体字1: [offset list] }, { 繁体字2: [offset list] }] 就更好了。
同理简2繁。
我debug了一下是可以获取offset的,但是代码没办法修改,希望能给使用者更大的自由度。
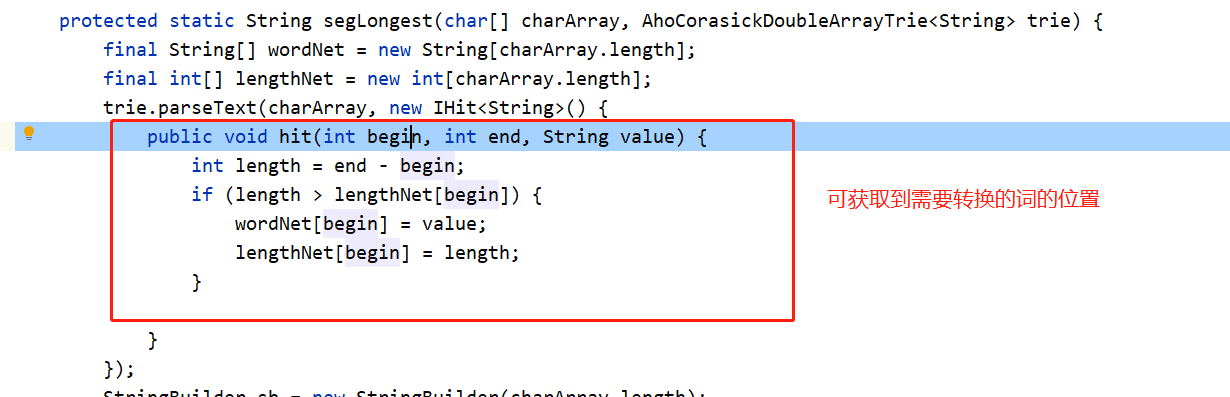
方法重写
继承
试试这种思路呢?
1赞
主要需要改到这个方法com.hankcs.hanlp.dictionary.ts.BaseChineseDictionary#segLongest(char charArray, DoubleArrayTrie trie)
这个方法TraditionalChineseDictionary和SimplifiedChineseDictionary都调用了,只是词典用的不一样。
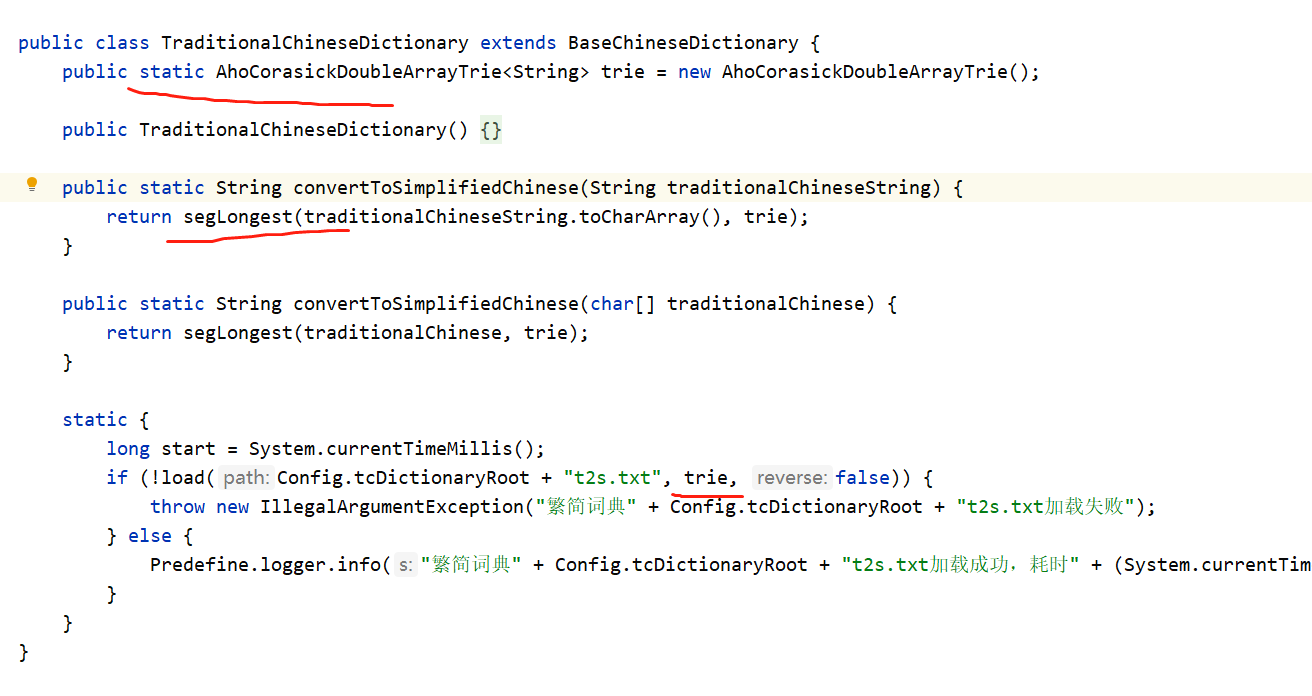
试了下没办法通过继承和方法重写来增强这个转换功能,因为AhoCorasickDoubleArrayTrie对象是静态的。
所以我看了部分源码,将其抽出来自己封装了。
原繁简转换,无法知道哪些是繁体字or简体字,也无法再转回原文。
具体改造请见:https://github.com/stefanxfy/hanlpHelper
2赞